
Résumé :
En 2015, l’équipe de l’Administrateur général des données au sein de la DINSIC a développé en collaboration avec le Service des technologies et des systèmes d’information de la Sécurité intérieure (ST(SI)è), un modèle de prédiction des vols liés aux véhicules. Cette collaboration a permis de développer Predvol, un outil d’aide à la décision pour les policiers et les gendarmes, comprenant une prédiction quotidienne du risque de vols, une carte de l’historique des vols et une typologie des quartiers en fonction de la nature des infractions qui y sont commises.
Ce projet, qui fut l’un des premiers de l’AGD, vit le jour lors d’une rencontre entre Etalab et le ST(SI)è. Les responsables du ST(SI)è, soucieux de tirer parti des avancées en matière de data-sciences, cherchaient un appui scientifique pour expérimenter des techniques d’apprentissage automatique (machine learning) sur un territoire. Le département de l’Oise, particulièrement exposé aux vols de voitures, réunissait les conditions pour lancer un projet.
Définir une problématique claire est indispensable au démarrage d’un projet de data-sciences. S’agissant des vols de voitures, nous sommes partis du constat suivant :
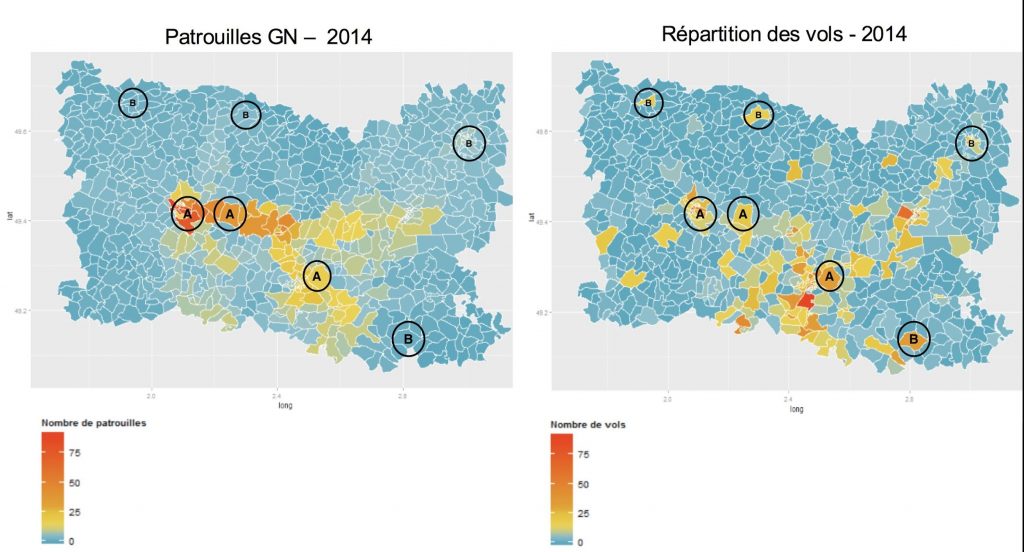
Un simple coup d’œil permet de s’apercevoir que certaines zones très surveillées par les forces de l’ordre, observent aussi de nombreux vols de véhicules (zones A), tandis que d’autres, bien que très touchées par les vols de véhicules, sont très peu empruntées par les patrouilles (zones B).
Dans quelle mesure serait-il possible d’anticiper les vols de voitures afin d’aboutir à une meilleure orientation des patrouilles de police et de gendarme ?
Afin de répondre à cette problématique, le ST(SI)è nous a transmis des données provenant directement des bases de dépèts de plaintes auprès de la police et de la gendarmerie : LRPPN et LRPGN. En tout, 3 ans d’historique de vols liés aux véhicules en ont été extraits. Chaque ligne correspondait à une infraction définie par un lieu (coordonnées XY), une date ainsi que quelques informations – souvent manquantes – sur le véhicule volé.
Par ailleurs, un contact régulier avec les utilisateurs finaux s’est très vite imposé afin d’identifier précisément les problématiques des acteurs de terrain et leurs façons de travailler. Deux besoins très distincts ont tout de suite fait surface :
1) Cibler les zones les plus à risques en amont de la patrouille
2) Un outil d’aide à la décision pendant la patrouille
Sur ce premier point, il convenait tout d’abord de définir un découpage géographique optimal afin d’entraîner nos algorithmes. Le découpage IRIS proposé par l’INSEE, apportant le meilleur arbitrage taille/quantité de données disponibles, s’imposa comme le meilleur candidat. Ce dernier permit en effet d’enrichir notre base de données d’apprentissage avec plus de 600 variables socio-démographiques sur ces zones (taux de chèmage, scolarisation des jeunes, nombre de commerces à proximité, èges moyens, ‘). Ajouté à cela, nous avons calculé d’autres indicateurs sur les circonstances temporelles des vols : Y-avait-il eu un vol la veille ? L’avant-veille ? Dans les quartier voisins ? Quelle était la météo du jour ? ‘
Le principe est en effet d’amener, sans a priori, le maximum de variables dans notre base de données (ici plus de 650 variables) puis de laisser les algorithmes de machine learning sélectionner les meilleures prédicteurs pour anticiper les vols de voitures.
Nous avons alors testé 3 grandes familles d’algorithmes afin d’anticiper au mieux, chaque jour, les vols liés au véhicules dans les 799 quartiers l’Oise :
A) Des algorithmes basés sur une grande quantité de variables
Ces algorithmes figurent parmi les plus classiques de la littérature en matière de machine learning : régression logistique, forèts aléatoires, boosting, forèts aléatoires extrèmement randomisées, XGBoost’ Ces algorithmes utilisent une très grande quantité de variables, sélectionnent les meilleurs prédicteurs en leur associant des pondérations et les utilisent pour tenter anticiper la variable d’intérèt.
B) Les algorithmes de PredPol, une entreprise américaine connue dans ce domaine
Revendiquant la place numéro 1 en matière de predictive policing, la société PredPol utilise des algorithmes initialement développés par un sismologue français, David Marsan, afin de prédire les répliques des séismes. PredPol a fait l’hypothèse que les crimes se comportent comme les séismes :
– il existe un risque-terrain : des zones plus sujettes au crime (calculé en fonction du passé)
– les crimes entraînent des répliques (on parle d’effet de « contagion ») c’est-é-dire que lorsqu’il y a un crime dans une zone, la probabilité qu’il en survienne un autre dans une zone géographique proche est plus grande et décroét avec le temps.
Nous avons implémenté leurs algorithmes et les avons testé sur les vols liés aux véhicules. Voici les résultats :
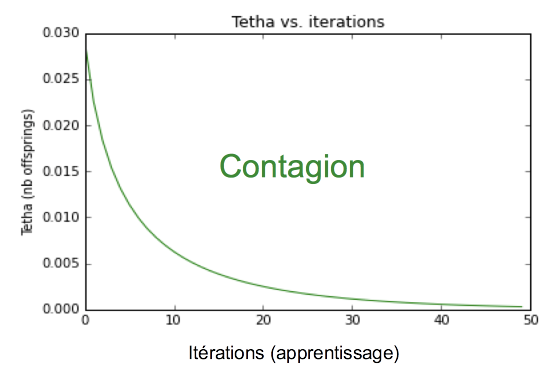
Deux constats :
- Les vols de véhicules dans l’Oise n’ont pas de mémoire (Tetha’0).
- Seuls le « risque terrain »du quartier est important.
Ce deuxième constat nous a alors conduit à tester notre troisième algorithme.
C) Les cartes de chaleurs évolutives
Une carte de chaleur est finalement exactement comme le modèle de PredPol sauf qu’on enlève la complexité du facteur de contagion. On prédira comme zone la plus risquée demain, la zone dans laquelle ont été observés le plus de vols dans le passé. Il convient désormais de définir ce fameux « passé ». En effet, la technique des « punaises sur la carte » (infractions du dernier mois) est toujours couramment utilisée par la police et la gendarmerie. Notre idée ici était de trouver l’historique optimal qu’il faut utiliser afin d’obtenir la carte de chaleur prédictive la plus pertinente.
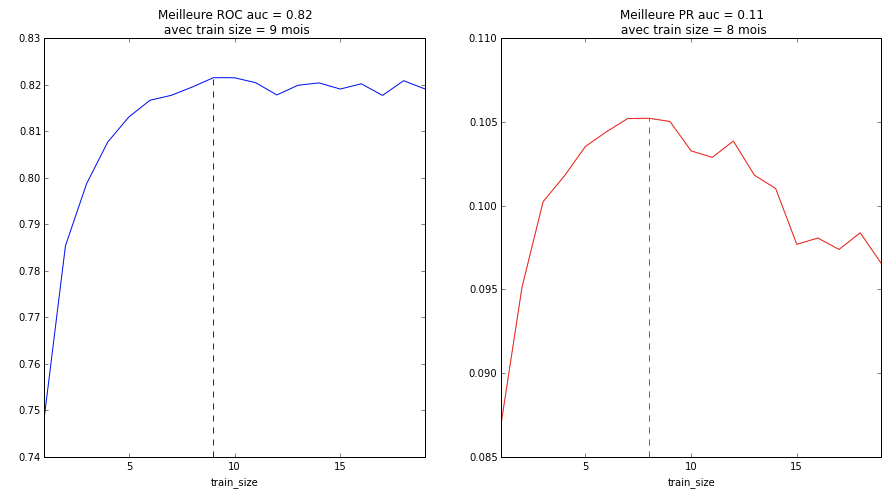
Nous avons comparé les différents historiques utilisés selon les deux facteurs clés d’un modèle prédictif : la capacité prédictive et la précision du modèle. Un historique trop petit (les fameuses punaises) pénalisent grandement la capacité prédictive du modèle, tandis qu’un historique trop grand pénalise sa précision. Afin d’obtenir le meilleur ratio capacité prédictive / précision, construire notre carte de chaleur sur neuf mois semblait le seuil optimal.
Une fois nos modèles construits, il s’agissait ensuite de les comparer. La méthodologie est très classique : les algorithmes ont été entraénés sur une partie de la base de données (la première année d’infractions) puis testés sur une seconde partie que les algorithmes n’avaient jamais vu (les deux dernières années). Les résultats furent sans appel :
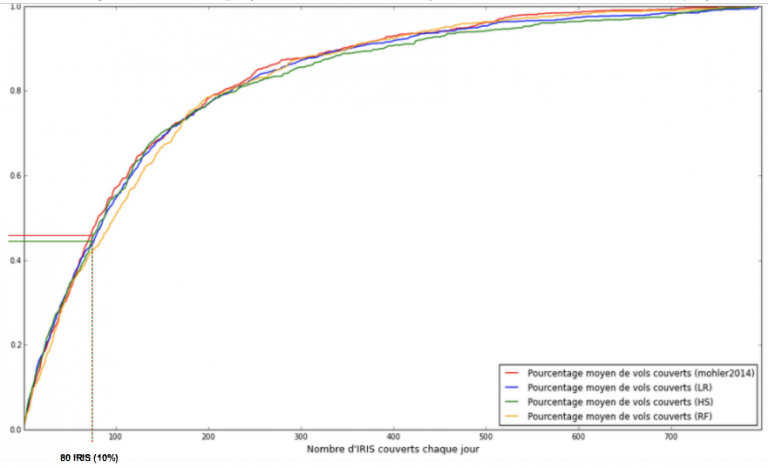
Les modèles prédictifs donnaient tous d’excellents résultats : cibler en moyenne 10 % des quartiers prédits les plus risqués par le modèle permettait de couvrir 50% des vols.
De plus, le modèle le plus simple (carte de chaleur prédictive) permettait d’obtenir des résultats quasiment identiques aux modèles les plus complexes (celui de PredPol, notamment)
Simple is Beautiful. Cet adage bien connu prit alors tout son sens. Pourquoi ajouter un coût en complexité important lorsqu’on peut faire presque aussi bien avec un modèle simplissime ? Cela est d’autant plus vrai dès lors qu’on envisage d’intégrer nos travaux lors de la mise en production dans les systèmes d’information de l’état dont les environnements ne sont pas toujours prèts é recevoir des calculs complexes.
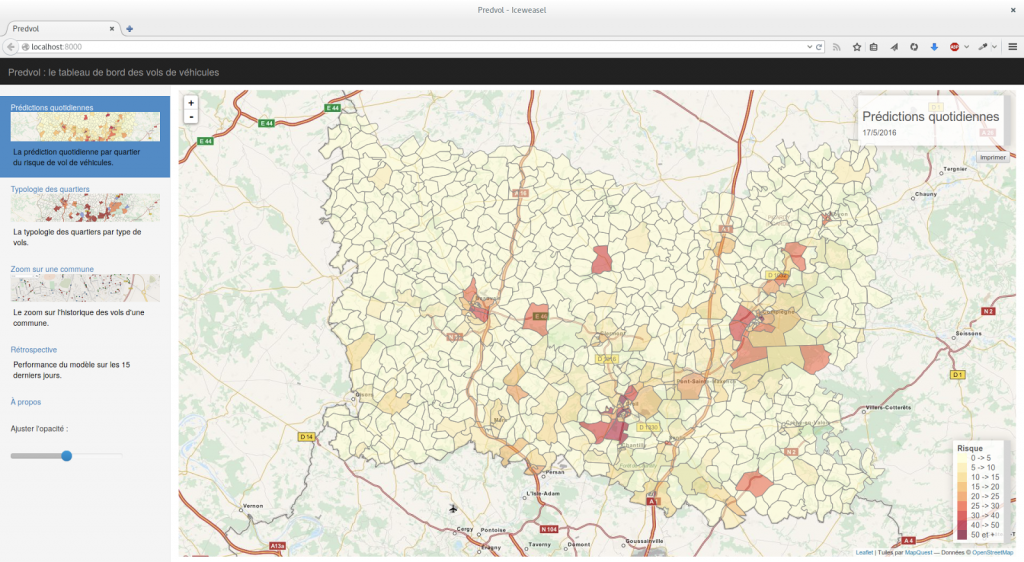
Le modèle choisi, nous avons construit un outil baptisé « PredVol », optimisé pour un usage en mobilité (sur tablette) afin de rendre disponibles les résultats des prédictions journalières aux opérationnels de terrain. Nous avons doté PredVol de 3 onglets, l’un permettant de visualiser les quartiers prédits les plus risqués par le modèle, le second affichant une typologie des quartiers en fonctions des types de vols les plus présents dans chaque quartier, et un troisième permettant de visualiser les faits passés sur une carte.
Côté Gendarmerie, l’outil a été intégré aux outils décisionnels et testé au sein de la compagnie de Compiègne à partir de mai 2016. Côté Police nationale, l’outil a été testé par les agents de la Direction départementale de la sécurité publique (DDSP) de Beauvais et notamment en patrouille par la brigade anti-criminalité (BAC).
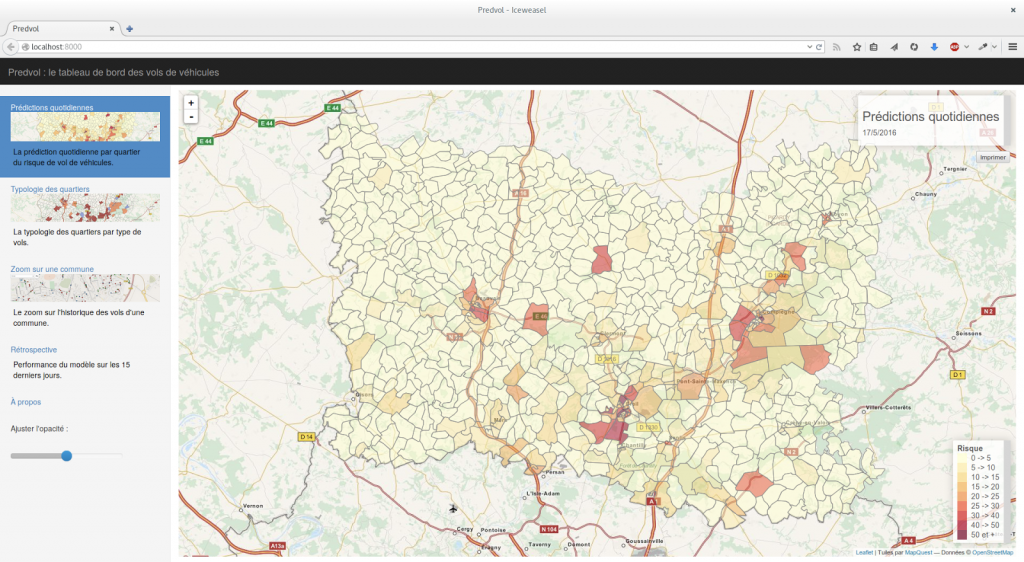
Pendant 6 mois d’expérimentation, nous avons eu l’occasion d’améliorer l’outil PredVol afin qu’il réponde au mieux aux usages opérationnels. Cette étape cruciale nous a par exemple permis, en patrouillant avec la BAC de Beauvais, de réaliser que les boutons de sélection étaient trop petits pour ètre utilisés dans les virages.éAprès 6 mois d’expérimentation, nous avons réalisé que l’essentiel de l’attention des patrouilles se dirigeait non pas sur les prédictions quotidiennes, mais sur la simple visualisation des faits passés. En effet,si les prédictions – bien que toujours très performantes – ne permettaient que de confirmer les zones é risques connues par les opérationnels, la simple visualisation des faits (onglet 3) représentait un très net progrès dans leur usage quotidien.
Fort de ce constat, nous avons développé un nouvel outil sur-mesure pour les brigades et cette fois entièrement porté sur la visualisation des infractions :
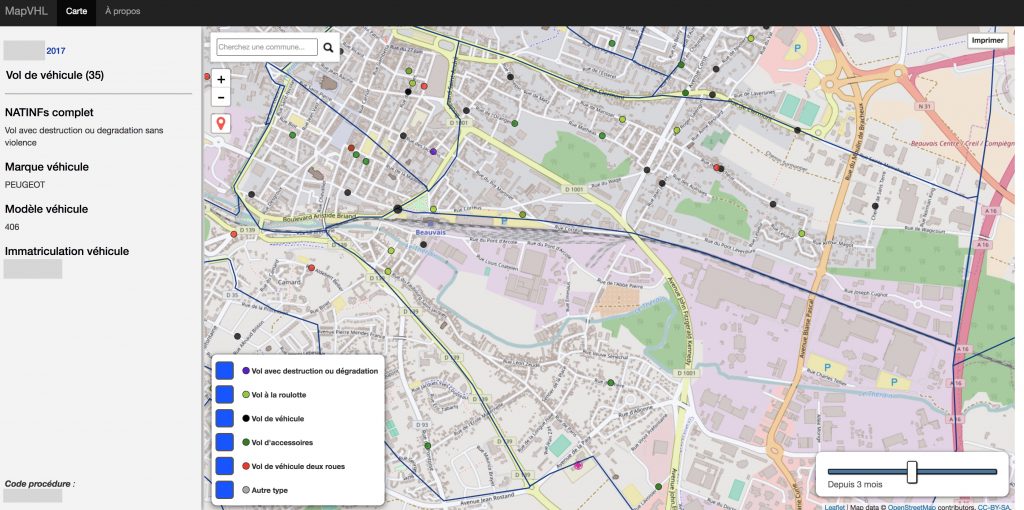
Ainsi qu’un autre permettant de visualiser les découvertes de véhicules volés, permettant ainsi aux brigades d’orienter leurs recherches lorsqu’un véhicule est volé, en fonction de sa marque et de son modèle.
Enfin, permettre aux agents du terrain de visualiser les faits qu’ils renseignent au moment des plaintes amorce un cercle vertueux : cela les encourage à recueillir des données de qualité, condition nécessaire – datascience ou pas – à l’obtention de résultats pertinents.